How Well Can GPT Do Scientific Literature Meta-analysis?

Generated using DALL-E.
TL;DR We implemented a GPT 4-based meta-analysis pipeline and results
copilot app, and undertook a concrete meta-analysis project with it. We wouldn’t
rely on GPT 4 to conduct a meta-analysis unattended, but classification
performance was decent, and in combination with application support it can
improve and accelerate a literature meta-analysis project.
AI is increasingly being used to assist scientists in their work, and one of the areas most immediately expanded by the advent of LLMs is analysis of the scientific literature. It would be a superpower for a researcher to use AIs to synthesize vast collections of existing research results and to answer questions about the body of research accurately and thoughtfully. Some ambitious projects in this space include Meta’s Galactica, Allen Institute for AI’s Semantic Scholar, at least one application of Google’s Gemini, and Paper QA.
In this post I report results on some concrete experiments in automated review of scientific literature using LLMs. The problem arose from a dinner table conversation with my wife Jen, a plant ecologist at UC Davis, about a literature meta-analysis project she’d been working on.
With her students she’d been aiming to answer a specific question for each of about 600 published scientific papers, and it had become challenging. She’d prepared a rubric in Excel, and asked a few of her students to go through an allotment of the papers one by one, classifying the papers according to the rubric. This approach was coherent, but there were several practical issues with it:
- There were so many papers, and the task so labor-intensive, that it was taking a long time to go through them.
- There were at times inconsistencies in how Jen and her students would classify a paper.
- Student time is reasonably expensive so the project cost a fair bit.
We wondered if LLMs might offer an effective alternative approach to the problem. If the accuracy was good, LLMs could be faster, more consistent, and less expensive than traditional “human-based” meta-analysis.
I looked for existing work on this specific area, and found just one published paper1: Qureshi et al (2023). This article is a commentary that expresses general caution about the prospect of using LLMs for literature meta-analysis. Qureshi et al wasn’t aimed at making a quantitative statement of how well LLMs might do in literature review, nor was it directed at any specific problem. I’d thought we might contribute a quantitative result on a concrete meta-analysis problem.
The Problem
Back in 2008, Jen and colleagues had published a paper in Trends in Ecology and Evolution (TREE), which argued that “plant functional traits” should be used to restore ecologically-degraded areas. Plant functional traits are what they sound like: the traits of plants, like root depth or leaf area, that help plants to function more or less ably in a given environment. The functional-trait approach is in contrast to the more traditional species-based approach: when you’re trying to restore a patch of land, should you select plants by species, or select them by function?
The 2008 paper had been cited a lot – more than 600 times – but Jen wasn’t convinced that researchers were considering traits prior to implementing restoration experiments. Many of the citing articles might be citing the 2008 paper as a manual, but some of the citations might be citing other aspects of the paper, some might be general lit reviews, some might even be diatribes against the whole functional traits paradigm…
Jen aimed to answer a specific question about each of the papers that cited her 2008 paper:
What proportion of the citing papers describe an experiment in which functional traits are an integral part of the experiment’s design?
If that proportion is large, that suggests that the use of functional traits for restoration may be pretty mainstream. If the proportion is small, perhaps the large number of citations means something else.
When the human-based meta-analysis became a slog, we wondered if LLMs might be able to handle the job. We’d seen that OpenAI’s GPT 4 performed startlingly well on the SAT, GRE, and LSAT exams, commonly registering at the 90th percentile or above. Since the questions we wanted to ask of the citing papers were essentially reading-comprehension questions like on the verbal sections of those exams, we thought GPT might be able to do well on this problem. But we’d also seen that GPT 4 hallucinates and can be confidently wrong.
So we undertook some experiments using GPT via OpenAI’s API, to see how well we could answer Jen’s question.
Approach
We treated this primarily as an exercise in prompt engineering with retrieval-augmented generation (RAG), i.e. we programmatically generated the LLM prompts by extracting text from the papers from a database.2 Our general strategy was to automate Jen’s spreadsheet rubric via OpenAI’s Chat API. Practically, this breaks down into four interacting components:
- data collection and preparation
- prompt engineering
- agent execution
- performance evaluation
The code to reproduce the analyses is provided at GitHub.
Data Collection and Preparation
We used Semantic Scholar to obtain a JSON-format list of all 632 papers citing Jen’s 2008 TREE paper.3 We downloaded PDFs of the open-access papers – 43% of the papers were open access – directly from the internet, and got the remaining papers through the UC library. The citing paper metadata and the PDFs were stored in a SQLite database that was convenient to use throughout the analysis.
We used Grobid to convert the text from each PDF file into XML format. This process organizes the paper’s content into a structured format, breaking it down into sections, paragraphs, and sentences.
We then stored each paper’s contents in a ChromaDB vector database sentence by sentence, along with metadata including the DOI, section heading e.g. “Materials & Methods”, location in the paper, and token count. We used Jina AI’s embeddings to map the sentence text into embedding space4. This allowed us to perform both syntactic and semantic searches on the text, described below.
Prompt Engineering
This was the most fascinating and challenging part of the project. This was mostly new for me, and I relied primarily on OpenAI’s and Anthropic’s excellent prompt engineering guides, as well as Jeremy Howard’s video guide.
The complete set of prompts ultimately used for the project is in the file
data/decision-tree.yaml
on GitHub.
[System Prompt] After experiments with longer system prompts (“You are a diligent, honest plant ecology graduate student…”) we ended up with a fairly compact prompt:
You are an autoregressive language model that accurately answers multiple-choice
questions about scientific papers.
You ALWAYS output your response as valid JSON, that adheres strictly following
schema, with the keys in the order given:
type Output = {
research: string; // To help you THINK carefully about your response, summarize
// the question and the relevant available evidence in your
// own words, in one hundred words or fewer
assessment: string; // Provide specific evidence for the choice of one option
// over the other, in forty words or fewer
response: string; // Your answer: "A" or "B"
confidence: number; // Scale: 1 (uncertain) to 5 (certain)
}
In order to process these in an automated way, I had it return JSON. The prompt above worked perfectly, in that invalid JSON was never generated.5
The research key was added on the advice of all three sources mentioned above
to “prime the pump”, and it empirically seemed to help.
[Question Sequencing] We followed Jen’s rubric-based approach for classifying the papers, building up to our ultimate question via a sequence of simpler preliminary questions, as strongly advised by all of the prompt guides. Here was the decision tree we used, at a high level (the exact text is here):

[Response Format] By its design, GPT tends to want to be helpful and affirming. In this context, that quality was detrimental because we wanted GPT to make objective assessments rather than just agree, so we did two things to try to ameliorate the issue:
-
Try not to lead the question, by phrasing the question as two mutually-exclusive alternative hypotheses, as opposed to an alternative hypothesis that we might seem to favor vs a less-favored null. To illustrate the idea:
BAD:
Is this article a review?BETTER:
Which is more likely to be the case? [A] This is a review article. [B] This is an original research article, methods paper, or case study. -
Randomize the order of the two alternative responses.
[Phrasing] The distinction that we’re asking GPT to make here is ultimately somewhat subtle. There are papers where Jen needed to explain, slowly 😀, to me why she’d classified a paper as she had. This was the most intellectually interesting part of the project, i.e. working as a liaison between the domain expert and the LLM.
[Retrieval Strategy] When we began this project, there were two reasons that RAG was important:
- There was a 4096-token context limit on GPT 4 queries, and the median token count for the papers in this collection is 7200 tokens, with a max of about 13K. You’re thus obliged to use a selection of the text from the paper, and leave space for your questions and GPT’s responses.
- Queries cost money.
OpenAI’s November 6th DevDay obviated the first reason, when they announced that GPT 4 would now be available with a context length of 128K tokens, plenty of room to embed to entire text of any of the papers with plenty of room to spare.
The second reason still applies though. While GPT 4’s prices dropped substantially with the new announcement, with these payload sizes you’re still working in dollars, not cents, in a typical R&D session, and the distinction between selected text and all text implies a factor of perhaps 3-10X in the cost to run the entire meta-analysis.
The retrieval goal here was to take the K sentences most informative to our questions from the vector store. To do this, we did semantic – i.e. embeddings-based – searches for sentences that were related to either of two questions, one about whether the article concerned an original empirical experiment, and a second about whether the article concerned plant functional traits.
In practice I found that semantic search was not enough. The semantic search results were usually reasonable, but I observed on reviewing the results against the paper text that there were commonly sentences that described the experiment, or that clearly concerned functional traits, that I would have forwarded to the prompt myself, but did not come up in the semantic search.
So I added a syntactic search by searching for sentences that included any of a list of substrings, e.g. “experiment*”, “manipulat*”, and combined these sentences with the set produced by semantic search. That seemed to catch most of the sentences that seemed to me like they should have been selected.
That would often produce more sentences than the token limit allowed, so I thinned the sentences by iteratively discarding one sentence from the two currently-closest pair of sentences in embeddings space until the token limit was met.

The text of both the syntactic and semantic queries is
here
under excerpt_configuration.
Agent Execution
The “agent” is the LangChain-based python program that actually evaluates the papers.
I used a graph structure to represent the classification decision tree, and the program traverses this graph to evaluate the decision tree. For each article, the agent:
- Constructs the prompt using text from the document
- Sends it to OpenAI’s API
- Parses the results
- Decides whether to halt, or to loop back to construct the next prompt
- Stores the results
Performance Evaluation
I treated this as a classification problem, because the system is ultimately classifying each paper into exactly one of the terminal states in the graph. For each experiment we ran then, we had an expected class as assessed by Jen, and the observed class that came from our LLM system.
With that framing in place, we can use the usual classification assessment tools, e.g. accuracy/precision/recall etc, to evaluate the performance of the system.
For the purposes of evaluation, we prepared two datasets, the training set and the test set:
Training Set
For “training” and validation6, we created a dataset of 48 papers, where we chose ten papers at random from each of the five terminal nodes/classes, as established by the preliminary classifications done by Jen’s students.7 We reasoned that a stratified sample like this would give us the best chance to explore the boundaries between each of the terminal classes. Jen reviewed those initial classifications, and reclassified a few of the papers.
We used this set to revise the prompts repeatedly, which could induce bias in the results. We present the performance results from our final model on the training set for posterity, but because of the potential bias we also created a test set.
Test Set
To get an unbiased set of papers, we drew another 25 papers from the set of all papers that were not in the training set, this time without respect to their preliminary classification by the students, i.e. that were “unstratified”. Jen classified the papers before we ran the LLM classifier over them. These results should then represent a fair test of the accuracy of the classifier.
Results Browser App
To help review the results, I wrote a Streamlit app to view the results from the various experimental runs. All the source data and results were stored between the Metaflow service we’d used to run the experiments and a single SQLite database file, so it was convenient to show the results and the paper pdf juxtaposed with one another in the app. I also added a “Notes” field to save notes into the database as we reviewed the results, which was convenient.
Here’s a screenshot of the results-browsing app. We’ve also put up a live version of the app here if you’d like to try it; it contains the subset of papers from the training set that were open-access. (Notes: It was designed for use with a wide monitor, which looks bad on a non-wide monitor, so it defaults into a non-wide mode I added. And saving notes is disabled.)

There’s a summary page that shows the overall statistics from a run, and then per-paper pages that show the dialogue between the program and the LLM. The main thing we’d do with the app is to review that dialogue to see where and how a classification effort would go awry.
With tools like these, writing a chat assistant with a custom interface like this is straightforward these days, and this may have been the most valuable outcome from this project. We’ll say more on this below.
Results
First we’ll show a concrete example of a dialogue between our agent and GPT 4:
Example LLM Dialogues
This is the sequence of responses for
Yanelli et al (2020)
with DOI 10.3389/fevo.2020.00238,
a correct classification, which you can see
for yourself in the app if you like. To save space, we don’t show the prompt, we
don’t show the “response” key – i.e. A or B – because all responses were
correct in this case, and we don’t show the “confidence” key, which we didn’t
end up using.
In the first question, GPT 4 correctly identifies Yannelli et al as an experimental paper, as opposed to a review:
research |
The question asks whether the article describes an experimental manipulation or an observational study/analysis. The provided excerpts mention an 'experimental design', 'additive experiment', and 'greenhouse experiment' with control and treatment groups. |
assessment |
The article clearly describes an experimental setup with control and treatments, indicating it reports on an experimental manipulation. |
Next, GPT 4 correctly finds that plant functional traits feature prominently in the article:
research |
The question asks if the article substantively involves plant functional traits. The excerpts mention using traits to categorize species into functional groups and list traits like canopy height, shoot morphology, and seed mass. |
assessment |
The article discusses categorizing species into functional groups based on traits and lists specific traits, indicating substantive involvement of plant functional traits. |
Last, GPT 4 finds that those functional traits were indeed used to design the experiment:
research |
The question asks if plant functional traits were integral or incidental to the experiment's design. The article mentions using traits to categorize species into functional groups, which suggests they were part of the experimental hypothesis. |
assessment |
Functional traits were used to select species for the experiment, indicating they were integral to the experimental design and hypothesis. |
These are each concise, textbook-correct answers to these questions.
For an example of what it looks like when GPT 4 fails, we show Yu et al
(2020), with DOI
10.1002/ece3.6938, which may also be viewed in the results app.
Jen classified it as falling in the penultimate bucket traits-not-in-design,
and while GPT 4 correctly identified this paper as (1) reporting original
experimental results and (2) involving functional traits, it then incorrectly
concluded that functional traits were integral to the experimental design:
research |
The question is whether plant functional traits were integral or incidental to the experimental design. The excerpts indicate that traits like plant height, seed germination, and photosynthetic efficiency were measured and considered significant in competitive exclusion, suggesting they were integral to the hypothesis. |
assessment |
Traits such as seed germination, growth speed, and photosynthetic efficiency were measured and linked to competitive exclusion, indicating they were integral to the experiment's design. |
GPT 4’s answer sounds pretty reasonable, but in this study functional traits were only measured after the fact, and not used as part of the experiment’s hypothesis. The prompt is explicit about this distinction, because it was one of the common failure modes, but GPT 4 doesn’t see it in this case.
Even so, when a (human) reader is aware that measuring traits only after the fact is a known failure mode, the phrase “traits … were measured and considered significant in competitive exclusion” in the response raises suspicion that this paper might be such a case. This is one reason why it may take less time to review and correct this classification in the context of GPT 4’s assessment than it would de novo, i.e. treating GPT 4 results as a preliminary assessment to be reviewed.
Now we’ll show the performance for the main configuration we’d been targeting, a GPT 4 model with a 1200-token limit on the content excerpted from the paper in question.
Training Set Performance
This confusion matrix shows how well the classifier did at the level of the individual papers. “Expected” is Jen’s reference assignments, and “Observed” is the output of the LLM classifier. Perfect classification would have all values falling on the diagonal.
Qualitatively, much of the weight does fall on or near the diagonal, but misclassification is not uncommon.
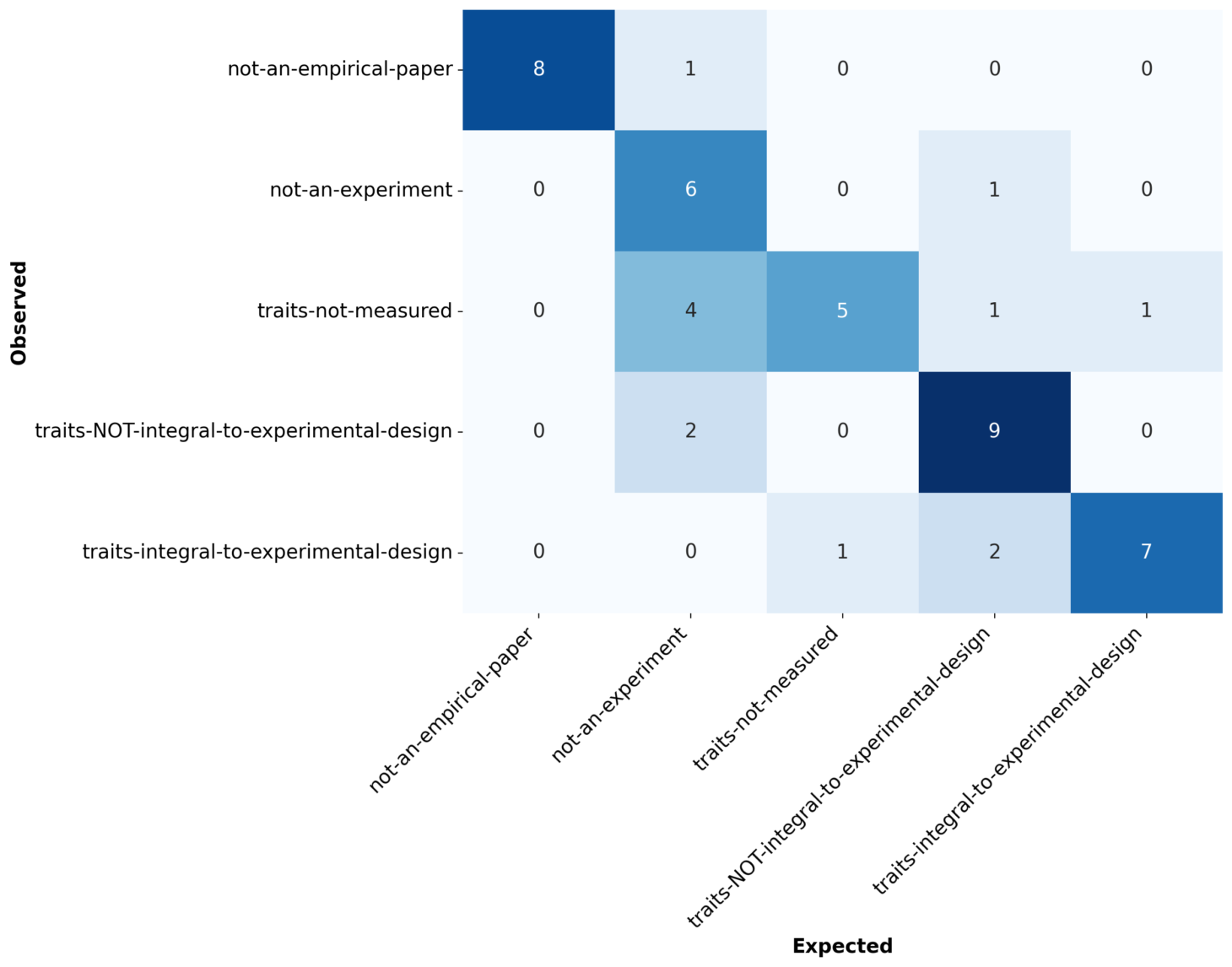
We summarize these counts using standard classification statistics. These are
each computed with functions from the sklearn.metrics module, using its
average="weighted" option where applicable to deal with potential class
imbalance. “MCC” abbreviates “Matthews Correlation Coefficient”. The 95%
confidence intervals are computed from 1000 bootstrap draws.
| Metric | Value (Confidence Interval) |
|---|---|
| Accuracy | 0.730 (0.625 — 0.833) |
| Precision | 0.775 (0.689 — 0.882) |
| Recall | 0.729 (0.625 — 0.833) |
| F1 Score | 0.726 (0.606 — 0.835) |
| MCC | 0.676 (0.545 — 0.798) |
Just guessing the classification at random would imply an F1 score of 0.5 and an MCC of 0.0, so the classifier is clearly capturing some of the signal. On the other hand, perfect classification would imply a 1.0 value for either F1 or MCC, and we are far from that standard.
Since we do care especially about the distinction between the “final” class –
traits-integral-to-experimental-design – vs the other classes, we compute the
same statistics as above, now collapsing the four other categories into a single
class:
| Metric | Value (Confidence Interval) |
|---|---|
| Accuracy | 0.917 (0.854 — 0.979) |
| Precision | 0.928 (0.875 — 0.981) |
| Recall | 0.917 (0.854 — 0.979) |
| F1 Score | 0.920 (0.856 — 0.980) |
| MCC | 0.734 (0.498 — 0.931) |
These “two class” statistics are improved across the board from the multiclass version, which makes sense because we’re not being punished for errors made within the first four classes, but the qualitative picture remains similar: classification performance is just decent.
Test Set Performance
Here’s the confusion matrix and statistics from the set of previously-unseen papers, now combining the multiclass and two-class statistics into one table:
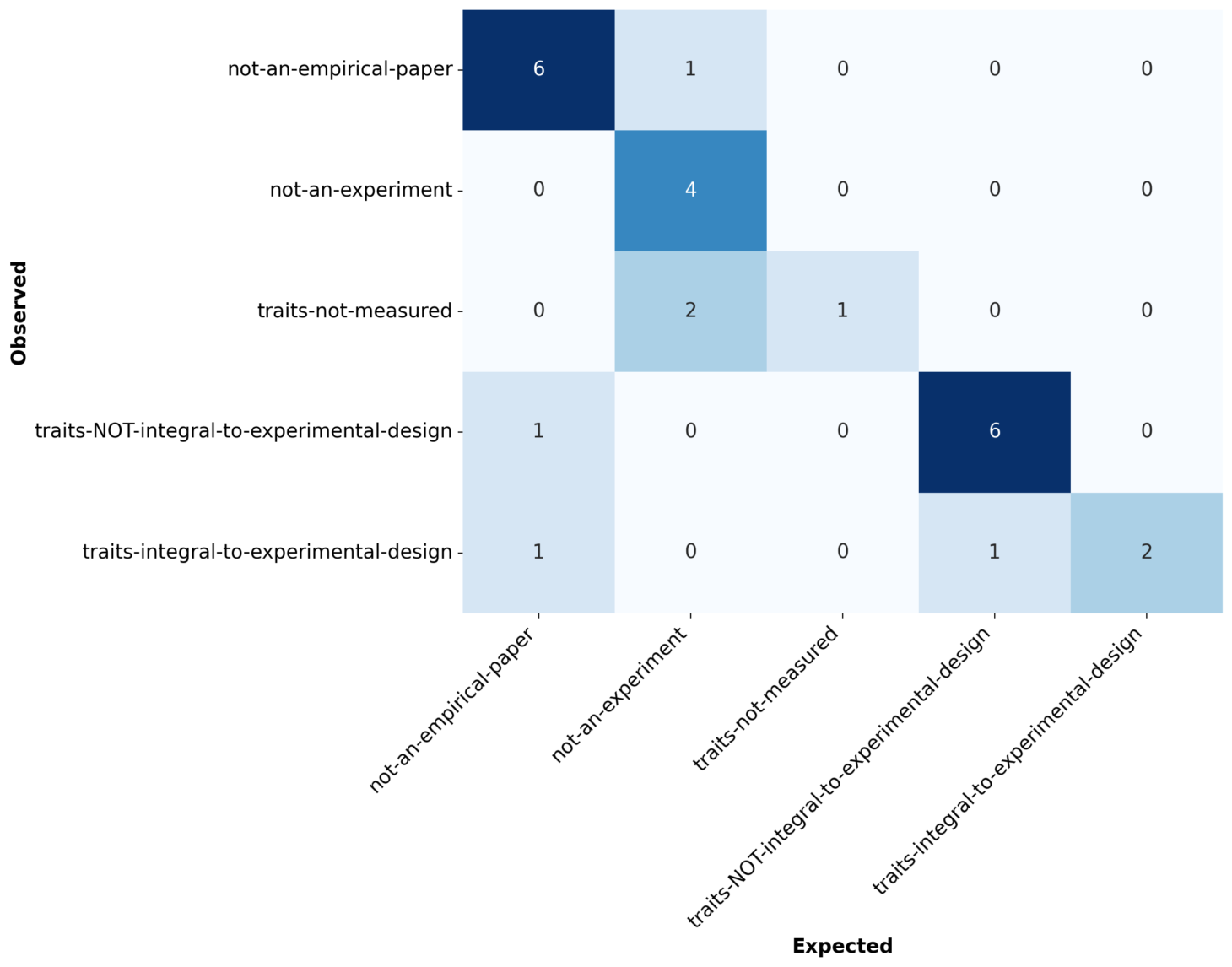
| Metric | Multiclass Value (Confidence Interval) | Two Class Value (Confidence Interval) |
|---|---|---|
| Accuracy | 0.760 (0.614 — 0.880) | 0.920 (0.840 — 1.000) |
| Precision | 0.848 (0.780 — 0.967) | 0.960 (0.931 — 1.000) |
| Recall | 0.760 (0.614 — 0.880) | 0.920 (0.840 — 1.000) |
| F1 Score | 0.773 (0.651 — 0.910) | 0.932 (0.864 — 1.000) |
| MCC | 0.702 (0.537 — 0.852) | 0.676 (0.000 — 1.000) |
The test-set performance is actually fairly similar to that in the training set, even though we’d tailored the prompts to do as well as we could on the training set papers. The F1 and MCC point estimates are both marginally higher in the test set, although the width of the confidence intervals suggest that “about the same” is probably a fairer assessment.
We do see some widely-discrepant classifications in the confusion matrix, that we hadn’t seen in the training set–far off-diagonal disagreements between the actual class and the observed class.
Performance on Other Variants
We evaluated the performance of the system under two further conditions:
- 1200-Token Limit vs Unlimited Tokens With the Nov 6th increase in the GPT 4 token limit, we can evaluate how well the classifier performed when it could see the entire paper.
- GPT 3.5 v GPT 4 GPT 3.5 is faster and much less expensive than GPT 4, and we used it for testing. How does it fare?
We summarize all of the results from the GPT 4 experiments in the following figure:

In the figure the horizontal line indicates the value of the statistic, the thicker line represents the 75% bootstrap confidence interval, and the thinner line represents the 95% bootstrap confidence interval.
Besides visualizing the results we’d presented above, this figure shows that providing the entire paper does not improve the accuracy of the classifications. The confidence intervals all overlap substantially, but in the two-class case the full-paper F1 score and MCC point estimates are actually lower (worse) than those of the excerpted text, for both the training and the test set.
This table summarizes the F1 score and MCC point estimates for all experimental conditions, including the GPT 3.5 experiments. The complete table of experimental results, including confidence intervals for all statistics, is here.
| Model | Class Grouping | Token Limit | Dataset | F1 Score | MCC |
|---|---|---|---|---|---|
| GPT 4 | Multiclass | 1200 | Training | 0.726 | 0.676 |
| GPT 4 | Multiclass | Unlimited | Training | 0.699 | 0.636 |
| GPT 4 | Multiclass | 1200 | Test | 0.773 | 0.702 |
| GPT 4 | Multiclass | Unlimited | Test | 0.849 | 0.805 |
| GPT 4 | Two Class | 1200 | Training | 0.920 | 0.734 |
| GPT 4 | Two Class | Unlimited | Training | 0.905 | 0.734 |
| GPT 4 | Two Class | 1200 | Test | 0.932 | 0.676 |
| GPT 4 | Two Class | Unlimited | Test | 0.902 | 0.590 |
| GPT 3.5 | Multiclass | 1200 | Training | 0.403 | 0.277 |
| GPT 3.5 | Multiclass | Unlimited | Training | 0.430 | 0.318 |
| GPT 3.5 | Multiclass | 1200 | Test | 0.569 | 0.509 |
| GPT 3.5 | Multiclass | Unlimited | Test | 0.623 | 0.575 |
| GPT 3.5 | Two Class | 1200 | Training | 0.745 | 0.155 |
| GPT 3.5 | Two Class | Unlimited | Training | 0.774 | 0.328 |
| GPT 3.5 | Two Class | 1200 | Test | 0.902 | 0.590 |
| GPT 3.5 | Two Class | Unlimited | Test | 0.886 | 0.534 |
As one expects, GPT 3.5 does not perform as well as GPT 4.
Cost
We present a table of costs for the final runs used in this writeup. All the values are in US dollars, rounded to the nearest cent. The average cost is the cost per paper in the dataset, and minimum and maximum costs are the least- and most-expensive individual paper in the dataset, respectively.
| Model | Dataset | Token Limit | Total Cost (USD) | Average Cost (USD) | Minimum Cost (USD) | Maximum Cost (USD) |
|---|---|---|---|---|---|---|
| GPT 4 | Training | 1200 | 1.86 | 0.04 | 0.00 | 0.07 |
| GPT 4 | Training | Unlimited | 11.85 | 0.25 | 0.04 | 0.51 |
| GPT 4 | Test | 1200 | 1.39 | 0.06 | 0.01 | 0.09 |
| GPT 4 | Test | Unlimited | 6.15 | 0.25 | 0.04 | 0.68 |
| GPT 3.5 | Training | 1200 | 0.25 | 0.01 | 0.00 | 0.01 |
| GPT 3.5 | Training | Unlimited | 1.12 | 0.02 | 0.00 | 0.05 |
| GPT 3.5 | Test | 1200 | 0.11 | 0.00 | 0.00 | 0.01 |
| GPT 3.5 | Test | Unlimited | 0.47 | 0.02 | 0.00 | 0.05 |
Although their accuracy is about the same, there is a big difference in the cost of the limited-token vs unlimited token versions, of about 6X (=11.85/1.86) more expensive for the training set, and 4X in the test set for the GPT 4 version.
If we were to run all 632 papers in the collection, that would be about \$25 using the 1200-token limit, and about \$155 using the full paper text. That’s more than a cup of coffee, but economical relative to the cost of a graduate student’s time.
Conclusions
This project explored the use of LLMs to assist with a literature meta-analysis in plant ecology. In our experiments, GPT 4 did not perform adeptly enough to conduct this meta-analysis unattended. GPT 4 nevertheless achieved decent performance in classifying papers according to our rubric, with moderately good F1 scores and MCC values.
As a copilot to help accelerate meta-analysis, GPT 4 is useful right now. For a modest cost relative to hiring a skilled human assistant, GPT 4 can screen large numbers of papers quickly, and provide summaries and provisional classifications to be reviewed by a domain expert. This, for what it’s worth, is how we plan to complete Jen’s analysis, i.e. to run the full 632 papers with a 1200 token limit, and modify the results browser app to suit her and her students' workflow.
Did we actually answer the original question, i.e. on whether the utility of functional traits to ecological restoration remains controversial? The test set results suggest that papers investigating functional traits’ utility in restoration might represent 10% of the papers that cite the 2008 TREE review, a number which can now be firmed up relatively quickly. Whether the precise final number is 5% or 20%, it’s not an overwhelming majority that would suggest that the field is consumed by this idea. So it seems unlikely that this particular meta-analysis will resolve the question. However, we do have a method to ask further questions of this or another corpus of articles relatively quickly and inexpensively, so additional meta-analyses may yet answer the question clearly.
It perhaps should not be surprising that we landed on a copilot, as opposed to an autopilot. The most popular applications of large transformer models – ChatGPT, GitHub Copilot, Stable Diffusion – all work by producing candidate outputs of varying quality, that need to be reviewed or refined by a human. This literature meta-analysis copilot works similarly.
The questions we were asking here involved subtle distinctions, that were sometimes challenging for even the experts to make. It was challenging to write the prompts to capture these distinctions, and we couldn’t do it perfectly. This particular problem might have been on the difficult end of systematic literature reviews, and one could imagine that questions with starker answers – e.g. “Which human disease conditions are discussed in this article?” – might show better classification performance than we saw here.
We’ve also discussed this as though it were purely a task to be optimized. However, there may be value to a graduate student – to anyone – in the process of carrying out a meta-analysis manually themselves, in the sense that they might e.g. develop a deeper understanding of a problem. This is similar to the concern that the introduction of electronic calculators might weaken human mental arithmetic skills. This is a topic for another day, that I’ll merely acknowledge here. I will note that (I think) I learned a reasonable amount about this topic myself through attempting to write clear prompts, so perhaps there is also pedagogical value in building and using an LLM copilot in projects like this.
Future work here might involve ensemble prompt strategies8, or if a large number of high-quality example classifications could be obtained, pursuing a fine-tuning approach. A literature meta-analysis tool like this one might be generalized and implemented as a user-friendly webapp or open source package.
Acknowledgments
Thanks kindly to Nick Furlotte for improving an earlier draft. Any/all errors are mine!
-
It seems plausible that there wouldn’t be that much yet on the topic, but I well might have missed relevant work. I’d be glad to be corrected! ↩︎
-
A reasonable alternative might have been, and might yet be, fine-tuning with examples, but prompt engineering seemed direct and apt. ↩︎
-
Google Scholar does report more citations than Semantic Scholar, 811 to 632 at this writing. We didn’t study the differences extensively, and if there’s some important difference in how the two services collect papers, that could lead to a bias in the estimates we report. As above, we selected Semantic Scholar largely because of the convenience in programmatic access. ↩︎
-
Why Jina AI’s, and not OpenAI’s embeddings? Mainly, I’d started with the best-seeming embeddings I could find on HuggingFace, from convenience and cost. OpenAI’s embeddings do appear to be qualitatively better than the Jina v1 embeddings used for these results, in the sense that the selected sentences made more sense to me. The OpenAI embeddings still missed some sentences that I would have expected to be selected, so I still wanted to fold in the syntactic-search results. Having done that, the combined results when using either Jina or OpenAI seemed pretty similar. I would be surprised if this choice had a qualitative effect on the results, but it’s definitely a thread that could be explored further. ↩︎
-
Almost never. When OpenAI enabled
gpt-4-1106-preview, we found that it was often adding Markdown fences around the otherwise-correct JSON, e.g.:```json {"research": "This paper focuses on ..." "summary": "...", ... } ```OpenAI has since added “JSON Mode” to the API, which guarantees that it will emit valid JSON, but for our purposes we modified our code to work correctly with this fenced input and had no further trouble. ↩︎
-
The scare quotes around “training” signify that we didn’t actually train any model here, i.e. modify any neural network weights. What “training” was done entailed teaching this human to write marginally less-bad LLM prompts. ↩︎
-
Two of the 50 papers were in Google Scholar but not in Semantic Scholar. I hadn’t noticed it wasn’t exactly 50 until writing this up, and by then had finalized the decision tree prompts and run the analyses. It didn’t seem worth it to rerun everything for the delight of the round number. ↩︎
-
For example, Graph of Thoughts. ↩︎